
pytesseract介绍:
pytesseract是基于python的ocr工具, 底层使用的是google的tesseract-ocr 引擎,支持识别图片中的文字,支持jpeg, png, gif, bmp, tiff等图片格式。本文介绍如何使用pytesseract 实现图片文字识别。
什么是ocr?
ocr(optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转换为机器编码文本的技术。通过数字方式存储文本数据更容易保存和编辑,可以存储大量数据,比如1g的硬盘可以存储数百万本书。
ocr可以做什么?
ocr技术可以将图片,纸质文档中的文本转换为数字形式的文本。ocr过程一般包括以下步骤:
图像预处理/文本定位/字符分割/字符识别/后处理,最初由惠普开发,后来google赞助的开源ocr引擎 tesseract 提供了比较精确的文字识别api,支持100多种语言,本文将要介绍的python库pytesseract就是基于tesseract-ocr 引擎。
环境要求:(win环境和liunx均可)
- python 3.6
- pil库
- 安装google tesseract ocr
- 系统:windows/mac/linux,我的系统是windows10
软件安装:(win环境支持)
tesseract ocr github地址:https://github.com/tesseract-ocr/tesseract
windows tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
mac和linux安装方法参考:https://tesseract-ocr.github.io/tessdoc/installation.html
安装时可以选择需要的语言包:
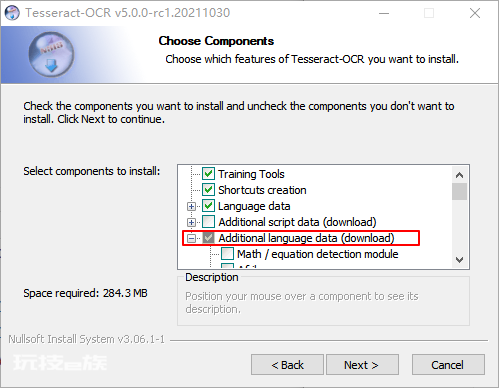
安装完成后,添加到环境变量path中,我的安装路径是:c:\program files\tesseract-ocr 。
命令行窗口输入:tesseract ,查看是否安装成功。
温馨提示:最好不要安装到c盘因为有些电脑需要管理员权限
安装pytesseract(python环境依赖)
pip安装pytesseract,python tesseract:
pip install pytesseract
程序案例:
适用场景:
想通过打印面单上面的文字是否存在,或者系统生成的pdf是否包含自己自定义的文字内容。
实现目标:
通过以上代码实现:当没有pdf路径时创建自动创建,再之前的步骤中已在路径下生成了pdf临时存在本地的指定文件夹路径下。
1.然后打开pdf,首先判断pdf中是否存在文本值,如果存在则打上标记。
2.获取pdf中所有的图片个数,然后将其按照 if pix.n - pix.alpha的方式判断是否格式可以存为png。
3.添加图片尺寸验证,防止图片过小。
4.pytesseract.image_to_string将图片转为文字,遍历所有图片将所有的文字合并返回结果。
部分调试:
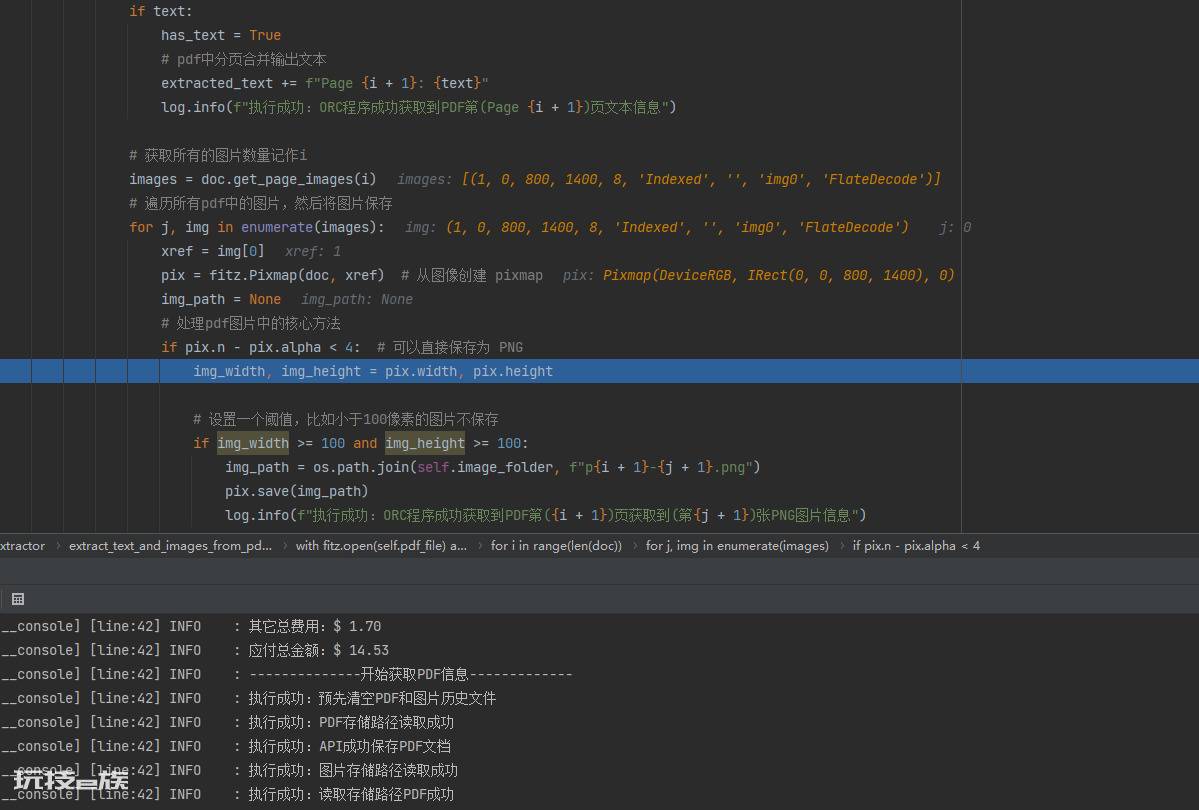
(图片获取结果)
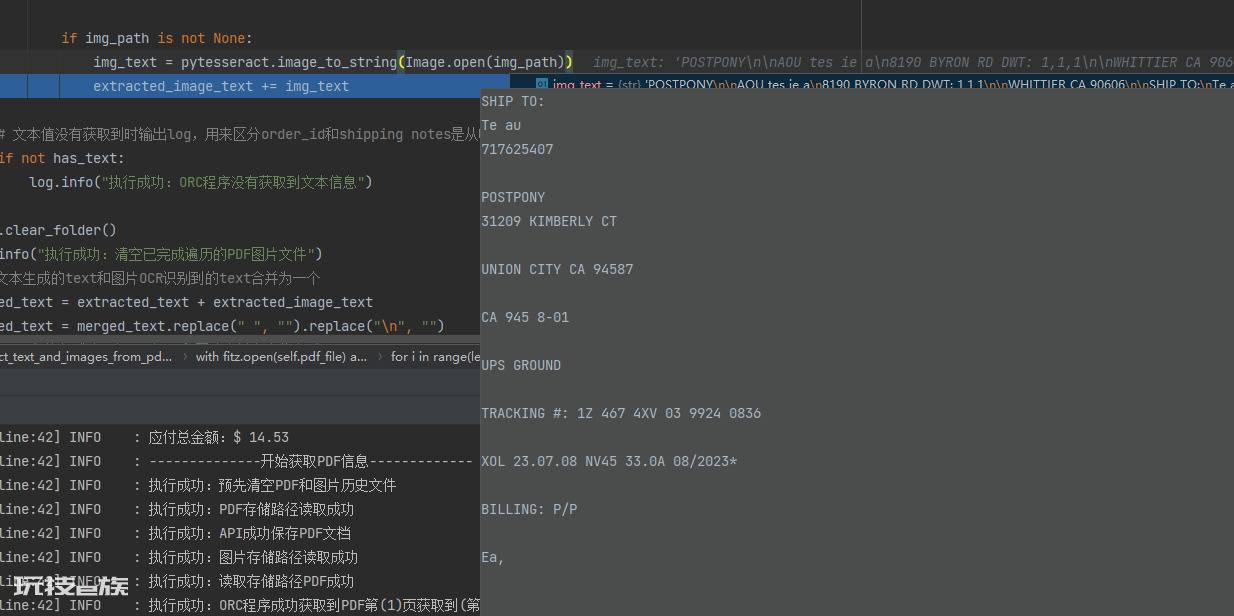
(图片转为text)
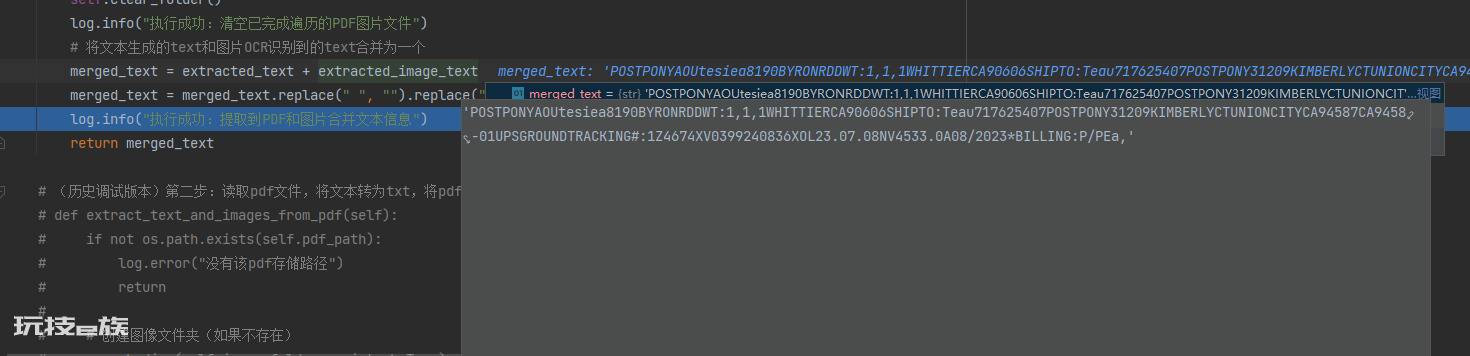
(合并输出结果)
风险通知:非原创文章均为网络投稿真实性无法判断,侵权联系
免责声明:内容来自用户上传发布或新闻客户端自媒体,切勿!切勿!切勿!添加九游会国际娱乐的联系方式以免受骗。

